

Les recommandations actuelles d’engrais sont effectuées à partir de guides généraux ajustés par les conseillers selon leur connaissance des facteurs locaux et suivant la règlementation en vigueur. Les guides de fertilisation couramment utilisés relèvent de concepts élaborés il y a environ 75 ans. Ils suggèrent un dosage moyen des engrais basé sur l’analyse de sol, des grilles de fertilisation, des valeurs estimées de contribution des fumiers, des résidus végétaux et de la matière organique, des considérations théoriques et des bilans de masse, ignorant les autres facteurs. Or, plus de 70 facteurs influencent la productivité végétale (Parent LE et al., 2021a). Les nombreux chercheurs qui ont contribué au guide de référence en fertilisation du CRAAQ en 2010 ont décrit les facteurs pouvant éclairer une décision de fertilisation à l’échelle locale.
Une fertilisation de précision ajustée aux conditions locales est appuyée par des technologies d’analyse spatiale, d’agriculture de précision, de pédométrie, d’hydrologie, d’acquisition et de gestion de bases de données de sources diverses ainsi que des prédictions de rendements, de doses optimales d’application et de pollution potentielle. Des zones d’intervention sont ainsi délimitées dans les champs à faible coût (Perron et al., 2018). Les recommandations d’engrais P et K dans les zones d’intervention sont demeurées celles des guides traditionnels de fertilisation sans ajustement aux facteurs locaux. Pour le dosage saisonnier de l’azote dans les unités de gestion, les méthodes d’imagerie spectrale seules sont peu précises (Khaireddine et al., 2013; Liu et al., 2020; Wen et al., 2021; Wang et al., 2021). Il faut incorporer dans les modèles prédictifs non seulement des images et des spectres mais aussi des propriétés de sol, des indices météorologiques, des pratiques de gestion et d’autres facteurs comme l’arrière-effet des réserves internes chez les cultures pérennes (Parent et al., 2021b).
Pour décortiquer le fonctionnement des agroécosystèmes locaux et faire les ajustements nécessaires, il faut avoir accès à un grand nombre d’observations fiables et être en mesure de les intégrer mentalement ou automatiquement. Ceci n’est possible qu’en bâtissant des bases de données standardisées, massives et diversifiées. La base de données est la gardienne de la mémoire collective et du savoir patrimonial.
Depuis la décennie 1990 au Québec, quelques chercheurs se sont fixés comme objectif de structurer les essais de fertilisation en bases de données communes, standardisées et bien documentées à l’échelle locale afin d’appuyer le conseil agronomique. Cette opération comportait plusieurs difficultés : manque de standardisation des données, unités de mesure variables, méthodes d’analyse différentes et saisie non uniforme des données. Il y avait aussi de nombreuses données manquantes et des erreurs d’entrée de données. Ceci dit, l’accès aux données demeure encore aujourd’hui un enjeu de premier plan et un défi de taille pour la mise en œuvre des technologies d’intelligence artificielle.
Récemment, des méthodes d’intelligence artificielle ont été testées avec succès pour intégrer plusieurs facteurs locaux dans les prises de décision en fertilisation. Elles peuvent en effet traiter une grande quantité d’information pour effectuer des prédictions de rendement et de dosage d’engrais spécifiques aux conditions du milieu. Ce texte vous introduit à la fertilisation de précision compte tenu de facteurs locaux documentés dans une base de données et analysés par des méthodes d’intelligence artificielle.
Efficacité d'utilisation de l'engrais
La réponse des plantes aux engrais montre généralement que le rendement marginal et l’efficacité d’utilisation de l’engrais diminuent de façon non proportionnelle avec la dose d’application (Figure 1). La trajectoire des courbes de réponse dépend d’interactions entre les éléments nutritifs (Dahnke et Olson, 1990) et de nombreux autres facteurs locaux (De Wit, 1992). On invoque souvent que la sous-fertilisation occasionne des pertes économiques plus importantes que la surfertilisation car la réponse de la plante aux ajouts d’engrais est décrite par des modèles de rendements décroissants. Les modèles théoriques de réponses utilisés en agronomie (Mitscherlich, quadratique) ont toutefois des trajectoires non linéaires peu flexibles qui s’ajustent plus ou moins bien aux données exprimentales même si celles-ci tendent à plafonner. Les modèles linéaire-plateau et quadratique-plateau ont forcé l’atteinte d’un plateau de rendement maximum oscillant autour d’une moyenne. L’ajout d’engrais sur le plateau est de toute évidence une utilisation inefficace de l’engrais qui peut générer un dommage environnemental.

L’efficacité d’utilisation des engrais est déduite du modèle comme la pente de la courbe de réponse (?rendement/?dose). Souvent élevée initialement dû à la forte pente initiale de la courbe de réponse jusqu’à une certaine dose, l’efficacité d’utilisation des engrais s’atténue avec l’augmentation de la dose jusqu’à devenir nulle ou même négative à forte dose. Le risque environnemental évolue dans le sens inverse car l’efficacité d’utilisation de l’engrais diminuent avec la dose : une plus faible proportion de l’engrais étant récupérée par la plante malgré un rendement plus élevé et une plus forte proportion étant déposée dans l’environnement. Une dose économique optimale est un compromis entre un rendement élevé, une haute efficacité d’utilisation de l’engrais et un impact environnemental faible.
Les recherches effectuées au Québec indiquent que le dosage optimal de l’azote et du phosphore dépendent largement des facteurs spécifiques au site (Coulibali et al., 2020; Parent SÉ et al., 2020a, 2020b). En effet, pour le maïs, la dose optimale d’azote varierait entre 0 et 300 kg N/ha sur les sites expérimentaux (Niyraneza et al., 2010; Kablan et al., 2017; Tremblay, 2020). La dose optimale de phosphore dépendrait non seulement de l’analyse de sol mais également d’autres facteurs comme le climat et la qualité du sol (Parent SÉ et al., 2020b). La surfertilisation consacre l’incapacité d’une approche traditionnelle à évaluer correctement la dose optimale d’engrais dans les unités de gestion spécifique.
Les engrais azotés et phosphatés ont un impact environnemental important. Les émissions d’oxyde nitreux (N2O), un GES 298 plus puissant que le CO2, sont de l’ordre de 1 % du taux d’application d’engrais azoté (Roy et al., 2014), ce qui suggère de ne pas dépasser la dose optimale (Omonode et al., 2017). La contamination des nappes phréatiques et des eaux de surface par les nitrates résiduels du sol après la récolte est également réduite avec un dosage optimal (Ziadi et al., 2013). D’autre part, le phosphore est un élément très déséquilibré dans les engrais de ferme, ce qui mène souvent à une sursaturation du sol en phosphore et à la pollution des eaux de surface. Pour réduire la pollution liée à la fertilisation, il faut augmenter l’efficacité d’utilisation des engrais et mettre en place des pratiques bénéfiques visant une dose optimale d’application compte tenu des facteurs locaux.
Une base de données fiables, partagées, massives et diversifiées
Pour comprendre le fonctionnement d’un système complexe comme un agroécosystème, il faut être bien informé. La courbe d’apprentissage du cerveau humain croît exponentiellement avec l’accumulation des faits et des connaissances (Figure 2). L’intelligence artificielle se comporte de la même façon.

Le plus grand obstacle au développement de l’intelligence artificielle est la forte résistance des organisations publiques, parapubliques et privées à partager les données requises pour permettre aux algorithmes d’apprendre des connaissances consignées dans une base de données massive et diversifiée. Des ententes de type FAIR (findable, accessible, interoperable, reusable) entre les parties prenantes pourraient faciliter ce partage (Geneviève et al., 2021) (Figure 3). Un protocole standardisé de partage des données devra être élaboré. Plusieurs domaines de la science sont interpellés à ce sujet, notamment la médecine et l’agriculture. Les sites suivants peuvent être consultés :
- https://portagenetwork.ca/fr/outils-et-ressources/glossaire-bilingue-de-la-gdr-francais-et-anglais/?cn-reloaded=1
- https://infocentral.infoway-inforoute.ca/en/standards/canadian
- https://science.gc.ca/eic/site/063.nsf/fra/h_547652FB.html
- https://bigdata.cgiar.org/communities-of-practice/ontologies/
- https://www.rd-alliance.org/data-standards-agriculture-inra-adoption-rda-outputs
- https://www.rd-alliance.org/recommendations-and-outputs/all-recommendations-and-outputs

Les données devront faire l’objet d’un classement selon les risques associés à la divugagtion et à la cybersécurité, ce qui implique de la règlementation et des contraintes selon leur classement. Les organismes subventionnaires exigent maintenant que les résultats de la recherche expérimentale soient saisis par les institutions subventionnées pour bâtir la connaissance commune. Qu’en est-il des données observationnelles? Comme dans le domaine médical, le consentement du fournisseur de données agronomiques sera sans doute nécessaire pour le partage des données. Un organisme indépendant et accrédité par les parties prenantes devra assurer la garde rapprochée des données patrimoniales fournies par les parties prenantes. En partageant les données, les parties prenantes verront rapidement les avantages de mettre en commun leurs données et les sécuriser.
Intelligence artificielle et agriculture de précision
Comme observateurs de première ligne, les producteurs se fient souvent à des systèmes performants qu’ils croient comparables aux leurs afin d’enrichir leurs connaissances et d’effectuer les correctifs qu’ils jugent fiables et nécessaires. Comme le ferait le producteur, les modèles d’intelligence artificielle développent des méthodes d’autoapprentissage pour "explorer le voisinage des objets" en recherchant la similarité entre les objets (Parent SÉ, 2021).
Les modèles d’intelligence artificielle comparent les données du producteur à celles d’un ensemble de cas similaires afin de prédire le dosage optimal des engrais et le rendement associé, réduisant ainsi les incertitudes sur la décision de fertilisation. Avec une abondance de sites bien documentés, ces modèles génèrent des doses optimales spécifiques au site et peuvent aussi vérifier la stabilité de ces doses sous diverses hypothèses comme les changements climatiques ou un changement de pratique.
Le modèle est entraîné avec une base de données pour étalonner les paramètres du modèle et une autre pour la validation du modèle. Des prédictions sont faites pour les données des unités de gestion fournies par le producteur, lesquelles sont consignées dans une base de données séparée. Une prédiction précise à 100 % est impossible à obtenir dû aux variations naturelles des facteurs sur le terrain, de la méthode d’évaluation du rendement (manuelle ou par machine) et des dimensions des parcelles qui peuvent varier de 20 m2 à 3600 m2 et même plus sur les sites documentés dans les bases de données. Les modèles exécutés jusqu’à présent par les méthodes d’intelligence artificielle se sont avérés assez informatifs pour évaluer le rendement et le dosage en appui à la fertilisation de précision (Coulibali et al., 2020; Parent SÉ et al., 2020a; Parent LE et al., 2020b; Betemps et al., 2020; Lima Neto et al., 2020).
Méthodes d’autoapprentissage
Les méthodes d’intelligence artificielle les plus connues sont les proches voisins, les arbres de classification et les réseaux neuronaux. Le modèle des proches voisins classifie les observations en calculant une distance entre une combinaison donnée de facteurs et celle d’autres observations. L’arbre de décision utilise une séquence hiérarchique de nœuds où se prennent des décisions booléennes sur l’appartenance à un groupe (oui/non, vrai/faux). Les réseaux neuronaux forment une architecture complexe de couches interconnectées de façon à maximiser la précision du modèle. Les méthodes d’apprentissage automatique peuvent être exécutées en mode de classification (probabilité d’appartenance à une classe) ou de régression (modèle de réponse).
Le mode de classification évalue la probabilité d’obtenir une valeur cible d’une observation supérieure ou inférieure aux valeurs visées par le modèle. Par exemple, le modèle peut calculer la probabilité d’obtenir un rendement de pommes de terre supérieur à 45 tonnes/ha sous les conditions spécifiées. Si la probabilité est jugée trop faible par l’utilisateur, le modèle recherche des cas à succès (> 45 tonnes/ha) pour des conditions comparables. La précision du modèle est mesurée comme la somme des spécimens bien classés (les vrais négatifs et les vrais positifs) divisée par le nombre total de spécimens. Si les facteurs déficients sont contrôlables, des pratiques bénéfiques sont mises en œuvre.
Le mode de régression permet de tracer une courbe de réponse aux engrais dans une unité de gestion donnée selon les facteurs spécifiés. Ceci requiert non seulement des données observationnelles fournies par les producteurs mais aussi des données expérimentales où la dose varie comme lors des essais de fertilisation. Une courbe de réponse est construite à partir des réponses mesurées sur des sites semblables au site diagnostiqué. La précision est mesurée par le coefficient de détermination de la relation entre le rendement prédit et le rendement mesuré.
Exemples de recommandation personnalisée
Des exemples de fertilisation de précision ont été publiés au Québec pour la pomme de terre (Coulibali et al., 2020) et le bleuet nain (Parent SÉ et al., 2020a). Les facteurs clés les plus importants et les mieux documentés ont été retenus pour la modélisation. La base de données fut divisée en données d’entraînement (70 %) pour paramétriser le modèle et de validation (30 %) pour tester la précision du modèle. La Figure 4 montre la prédiction du rendement en tubercules commercialisables et la courbe de réponse associée pour un cas répertorié dans la base de données de validation. La courbe de réponse peut être initiée à une dose minimale d’application comme une dose de démarrage ou toute autre dose (Kyveryga et al., 2007) plutôt qu’à la dose zéro requise pour calculer des rendements relatifs utilisés pour élaborer des grilles de fertilisation, ce qui facilite la conduite d’essais de fertilisation chez les producteurs.
Le modèle à saturation de Mitscherlich couramment utilisé pour simuler la réponse de la plante aux apports d’engrais indique que la pomme de terre se sature rapidement en azote jusqu’à 200 kg N/ha (Figure 4). Le modèle d’apprentissage automatique des proches voisins montre que la saturation de la plante en azote est atteinte à 150 kg N/ha dans le cas de cet essai. Une discussion avec le producteur montre qu’à la dose de 150 kg N/ha, les pertes en entrepôt sont minimes par rapport à une dose de 200 kg N/ha. Une dose élevée peut faire augmenter le rendement mais également diminuer la qualité des récoltes en affaiblissant les structures cellulaires de défense de la plante (Martinez et al., 2021), ce qui favorise les attaques parasitaires et les pertes en entrepôt. Dans cet essai, la pomme de terre a peu réagi au P au-delà de 30 kg P/ha et au K au-delà de 100 kg K/ha.
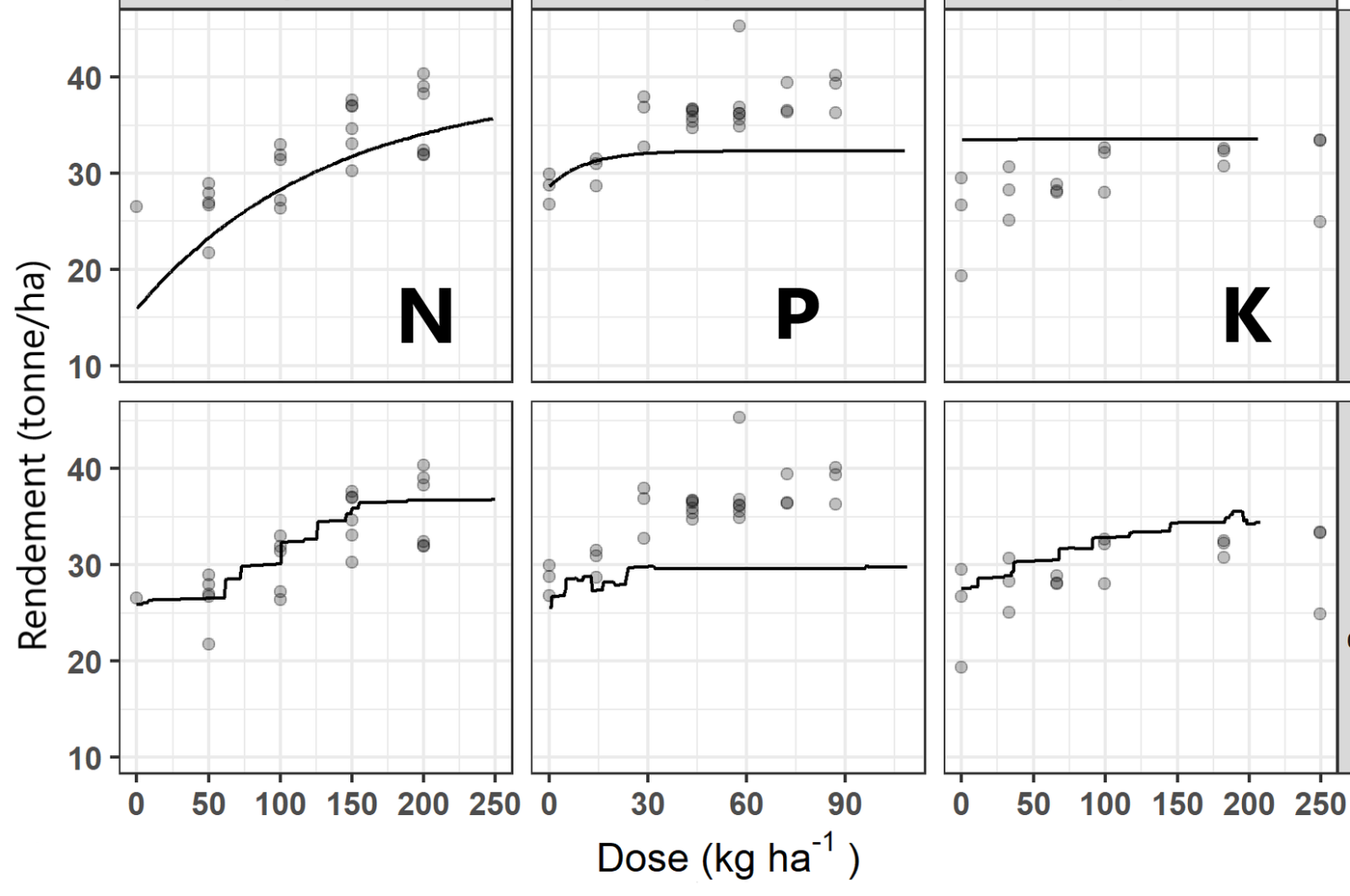
Notez que les rendements sont exprimés ici en tonnes par ha. Des rendements réels sont d’intérêt pour le calcul de la dose économique optimale d’engrais. C’est un net avantage sur les grilles de références en fertilisation qui sont construites à partir de rendements témoins (dose zéro) relatifs au rendement maximum ou de réponses aux engrais relatives au rendement témoin (% ou ratio). La recommandation suggérée dans les grilles de fertilisation correspond au niveau de probabilité qu’une dose optimale fonctionne sur l’ensemble des sites documentés dans cette grille, sans tenir compte d’autres facteurs spécifiques au site expérimental. Le modèle d’intelligence artificielle en tient compte.
D’autres méthodes d’optimisation peuvent itérer des doses d’engrais jusqu’à l’obtention d’une convergence vers une valeur optimale à partir d’une dose initiale. Ainsi, pour une unité de gestion dans une bleuetière de la région du Lac Saint-Jean, le modèle a suggéré des doses optimales combinées de 61 kg N/ha, de 14 kg P/ha et de 32 kg K/ha pour un rendement prédit de 5900 kg bleuets/ha (Figure 5). Ces prédictions permettent au producteur d’établir des cibles réalistes de rendement et de dosage d’engrais.

Des conditions optimales d’analyse de sol et de composition foliaire peuvent aussi être calculées à l’échelle de l’unité de gestion. Compte tenu des conditions locales dans une bleuetière de la région, des valeurs optimales de 130 mg Ca/kg, 64 kg K/ha, 26 mg Mg/ha et 39 mg P/ha ont été calculées pour les analyses de sol Mehlich-3 (Figure 6). Le pH optimal a rapidement convergé vers 4.6. Pour les conditions spécifiques dans une bleuetière de la région, Parent SÉ et al. (2020a) ont obtenu, après 20 itérations du modèle, les valeurs optimales suivantes de concentrations foliaires pour les éléments documentés dans la base de données : 2 % N, 0.15 % P, 0.48 % K, 0.44 % Ca, 0.14 % Mg, 0.,005 % B et 0.0045 % Al.

Transfert de l'information
L’intelligence artificielle ouvre des perspectives nouvelles à la fertilisation de précision. Bien que les modèles d’apprentissage automatique soient puissants, ils dépendent entièrement de la qualité des bases de données en termes d’uniformité, de fiabilité, de taille et de diversité. La collecte, le tri, le partage, la standardisation, le nettoyage, et l’imputation de données ainsi que le retour sur les données manquantes sont les étapes les plus exigeantes.
La mise en place d’une base de données commune et fiable permet aux "apprenants" artificiels de réduire l’incertitude sur le dosage optimal des engrais et les spéculations fréquentes sur les surdoses dites "de sécurité" (Kyveryga et al., 2007). Cependant, la décision finale revient aux décideurs qui intégrent le conseil agronomique, la stabilité du dosage, les connaissances locales et l’expérience personnelle du producteur (Figure 7).
L’amélioration continue de l’entreprise agricole vers l’agriculture durable peut inclure des essais de fertilisation à la ferme comme le suggère le guide de référence en fertilisation du CRAAQ (2010). Le producteur peut comparer son dosage actuel au dosage prédit pour tester le modèle. Des bases de données communes permettent d’améliorer continuellement la précision des modèles en rehaussant le niveau des connaissances le long de la courbe d’apprentissage (Figure 2). Si tous y contribuent à gravir la courbe d’apprentissage, la performance des modèles augmentera rapidement.

Conclusion
L’intelligence artificielle permet de réduire l’incertitude sur les doses optimales en ajustant les recommandations d’engrais aux facteurs documentés dans les unités de gestion. Il faut toutefois constituer des bases de données standardisées, fiables, massives et diversifiées. Depuis plusieurs années, les producteurs québécois collectionnent de grandes quantités de données observationnelles sous forme de programmes de fertilisation, de cartes d’agriculture de précision et autres cartes, de données météorologiques, d’imagerie spectrale et d’essais à la ferme, qui s’accumulent souvent dans des classeurs sans être valorisées. Les organisations publiques, parapubliques et privées ont aussi conduit plusieurs essais de fertilisation et saisi de nombreuses données expérimentales.
La taille et la diversité des bases de données peuvent être décuplées rapidement et à faible coût en combinant les données expérimentales des essais de fertilisation et les données observationnelles des producteurs. Ceci demanderait une mise en commun des données disponibles suivant un protocole rigoureux de sélection des variables d’entrées et de standardisation des données. Les données doivent être retraçables, accessibles, interopérables et réutilisables selon les termes des ententes entre les parties prenantes pour chaque type de production.
La mise en commun des données par le biais d’ententes de type FAIR entre les parties prenantes, comme c’est le cas dans d’autres domaines du savoir qui abordent des systèmes complexes, est une étape essentielle pour tirer un maximum d’avantages des puissants outils de l’intelligence artificielle. Les concepteurs d’algorithmes pourront alors élaborer des modèles d’apprentissage automatique performants pour la fertilisation de précision en appui au conseil agronomique et au développement durable de l’agriculture.
Lire le billet précédent
- Betemps DL, Paula BV, Parent SÉ, Galarça SP, Mayer NA, Marodin GAB, Rozane DE, Natale W, Melo GWB, Parent LE, Brunetto G. 2020. Humboldtian diagnosis of peach tree (Prunus persica) nutrition using machine learning and compositional methods. Agronomy 10, 900, doi:10.3390/agronomy10060900.
- Coulibali Z, Cambouris AN, Parent SÉ. 2020. Site-specific machine learning predictive fertilization models for potato crops in Eastern Canada. PLoS ONE 15(8): e0230888. https://doi.org/10.1371/journal.pone.0230888
- CRAAQ. 2010. Guide de référence en fertilisation. Parent LE, Gagné G (éditeurs). 2ième Ed., CRAAQ, Québec.
- Dahnke WC, Olson RA. 1990. Soil test correlation, calibration, and recommendation. Pages 45-72 dans: RL Westerman (éditeur). Soil testing and plant analysis. 3° édition, Soil Science Society of America Book Series #3, Madison, Wisconsin.
- De Wit CT. 1992. Resource Use in Agriculture. Agricultural Systems 40, 125–151.
- Geneviève LD, Martani A, Elger BS, Wangmo T. 2021. Individual notions of fair data sharing from the perspectives of Swiss stakeholders. BMC Health Services Research 21, 1007 https://doi.org/10.1186/s12913-021-06906-2
- Kablan LA, Chabot V, Mailloux A, Bouchard ME, Fontaine D, Bruulsema T. 2017. Variability in corn response to nitrogen fertilizer in Eastern Canada. Agronomy Journal 109, 2231–2242.
- Khaireddine N, Khiari L, Leblanc M, Cambouris A, Parent LE. 2013. Dependence of SPAD readings on nutrient balance in potato (Solanum tuberosum L.). Affiche, 13th International Symposium for Soil and Plant Analysis, Queenstown, New Zealand, 8th to 12th April 2013.
- Kyveryga PM, Blackmer AM, Morris TF. 2007. Disaggregating Model Bias and Variability when Calculating Economic Optimum Rates of Nitrogen Fertilization for Corn. Agronomy Journal 99, 1048-1056. doi:10.2134/agronj2006.0339
- Lima Neto AJ, Deus JAL, Rodrigues Filho VA, Natale W, Parent LE. 2020. Nutrient diagnosis of fertigated “Prata” and “Cavendish” banana (Musa spp.) at plot-scale. Plants 9, 1467; doi:10.3390/plants9111467
- Liu S, Yang X, Guan Q, Lu Z, Lu J. 2020. An Ensemble Modeling Framework for Distinguishing Nitrogen, Phosphorous and Potassium Deficiencies in Winter Oilseed Rape (Brassica napus L.) Using Hyperspectral Data. Remote Sensing 12, 4060; doi:10.3390/rs12244060
- Martinez DA, Loening UE, Graham MC, Gathorne-Hardy A. 2021. When the medicine feeds the problem; do nitrogen fertilisers and pesticides enhance the nutritional quality of crops for their pests and pathogens? Frontiers in Sustainable Food Systems 5, 701310. DOI: 10.3389/fsufs.2021.701310
- Nyiraneza J, N’Dayegamiye A, Gasser MO, Giroux M, Grenier M, Landry C, Guertin S. 2010. Soil and crop parameters related to corn nitrogen response in Eastern Canada. Agronomy Journal 102:1478– 1490. doi:10.2134/agronj2009.0458
- Omonode RA, Halvorson AD, Gagnon B, Vyn TJ. 2017. Achieving lower nitrogen balance and higher nitrogen recovery efficiency reduces nitrous oxide emissions in North America’s maize cropping systems. Frontiers in Plant Science 8, 1080. DOI: 10.3389/fpls.2017.01080
- Parent LE, Natale W, Brunetto G. 2021a. Machine Learning, Compositional and Fractal Models to Diagnose Soil Quality and Plant Nutrition. P. 1–23 dans: Soil Science - Emerging Technologies, Global Perspectives and Applications, IntechOpen FreeAccess, https://doi.org/10.5772/intechopen.9889
- Parent LE, Jamaly R, Atucha A, Parent EJ, Workmaster BA, Ziadi N, Parent SÉ. 2021b. Current and next-year cranberry yields predicted from local features and carryover effects. PLoS ONE 16(5): e0250575. https://doi.org/10.1371/ journal.pone.0250575
- Parent SÉ. 2021. Introduction to machine learning for ecological engineers. Nextjournal. https://nextjournal.com/essicolo/cc2020#
- Parent SÉ, Lafond J, Paré MC, Parent LE, Ziadi N. 2020a. Conditioning Machine Learning Models to Adjust Lowbush Blueberry Crop Management to the Local Agroecosystem. Plants, 9, 1401; doi:10.3390/plants9101401
- Parent SÉ, Dossou-Yovo W, Ziadi N, Leblanc M, Tremblay G, Pellerin A, Parent LE. 2020b. Corn response to banded P fertilizers with or without manure application in Eastern Canada. Agronomy Journal 112(3), 2176–2187.
- Perron I, Cambouris AN, Chokmani K, Gutierrez V, Ziebarth BJ, Moreau G, Bisqas A, Adamchuk V. 2018. Delineating soil management zones using a proximal soil sensing system in two commercial potato fields in New Brunswick, Canada. Canadian Journal of Soil Science 98(4), 724-737. https://doi.org/10.1139/cjss-2018-0063
- Roy AK, Wagner-Riddle C, Deen B, Lauzon, J, Bruulsema T. 2014. Nitrogen application rate, timing, and history effects on nitrous oxide emissions from corn (Zea mays L.). Canadian Journal of Soil Science 94, 563-573.
- Tremblay G. 2020. L’azote: comment s’y retrouver? Colloque IQHDO, 4 février 2020, Saint-Hyacinthe.
- Wang X, Miao Y, Dong R, Zha H, Xia T, Chen Z, Kusnierek K, Mi G, Sun H, Li M. 2021. Machine learning-based in-season nitrogen status diagnosis and side-dress nitrogen recommendation for corn. European Journal of Agronomy 123, 126193.
- Wen G, Ma BL, Vanasse A, Caldwell CD, Earl HJ, Smith DL. 2021. Machine learning-based canola yield prediction for site-specific nitrogen recommendations. Nutrient Cycling in Agroecosystems 121, 241-256.
- Ziadi, N, Cambouris AN, Nyiraneza J., Nolin MC. 2013. Across a landscape, soil texture controls the optimum rate of N fertilizer for maize production. Field Crops Research 148, 78-85. doi:10.1016/j.fcr.2013.03.02.